41 KiB

Translations:
Fordítások:
What is Regular Expression?
Mi az a reguláris kifejezés?
Regular expression is a group of characters or symbols which is used to find a specific pattern from a text. A reguláris kifejezés karakterek vagy szimbólumok egy csoportja, amelyet egy szövegből adott minták megtalálására használnak.
A regular expression is a pattern that is matched against a subject string from left to right. The word "Regular expression" is a mouthful, you will usually find the term abbreviated as "regex" or "regexp". Regular expression is used for replacing a text within a string, validating form, extract a substring from a string based upon a pattern match, and so much more.
A reguláris kifejezés egy olyan minta, amely illeszkedik egy adott karakterláncra balról jobbra. Maga a "Regular expression" kifejezést általában rövidítve lehet megtalálni, mint "regex" vagy "regexp". A reguláris kifejezést használják szövegrészek lecserélésére egy szövegben, űrlapok validálására, szövegrészek kiválasztására mintaegyezés alapján egy hosszabb szövegből és így tovább.
Imagine you are writing an application and you want to set the rules for when a user chooses their username. We want to allow the username to contain letters, numbers, underscores and hyphens. We also want to limit the number of characters in username so it does not look ugly. We use the following regular expression to validate a username:
Képzeld el, hogy egy alkalmazást írsz és szeretnél szabályokat állítani a felhasználónév kiválasztásához. A felhasználónév csak betűket, számokat, aláhúzásjelet és kötőjelet tartalmazhat. Szeretnénk limitálni a karakterek maximális számát is a felhasználónévben, hogy ne legyen csúnya. A felhasználónév validálására a következő reguláris kifejezést használjuk:
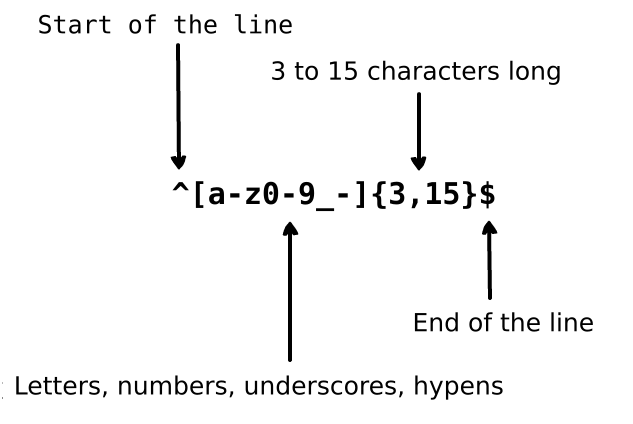

Above regular expression can accept the strings john_doe, jo-hn_doe and
john12_as. It does not match Jo because that string contains uppercase
letter and also it is too short.
A feljebbi reguláris kifejezés elfogadja a john_doe, jo-hn_doe és a
john12_as karakterláncokat. Nem fog egyezni a Jo-ra mert ez nagybetűt
tartalmaz és túl rövid is.
Table of Contents
Tartalomjegyzék
1. Basic Matchers
1. Bevezetés
A regular expression is just a pattern of characters that we use to perform
search in a text. For example, the regular expression the means: the letter
t, followed by the letter h, followed by the letter e.
A reguláris kifejezés egy karakterminta, amit keresésre használunk egy
szövegben. Például a the reguláris kifejezés a következőt jelenti: egy t betű,
amit h követ, amit egy e követ.
"the" => The fat cat sat on the mat.
Test the regular expression Teszteld a reguláris kifejezést
The regular expression 123 matches the string 123. The regular expression is
matched against an input string by comparing each character in the regular
expression to each character in the input string, one after another. Regular
expressions are normally case-sensitive so the regular expression The would
not match the string the.
Az 123 reguláris kifejezés illeszkedik a 123 karakterláncra. A reguláris kifejezés
minden egyes karaktere össze lesz hasonlítva a bevitt karakterlánc minden elemével
egymás után. A reguláris kifejezések alap esetben kis-nagybetű érzékenyek, tehát a
The reguláris kifejezés nem fog illeszkedni a the karakterláncra.
"The" => The fat cat sat on the mat.
Test the regular expression Teszteld a reguláris kifejezést
2. Meta Characters
2. Meta karakterek
Meta characters are the building blocks of the regular expressions. Meta characters do not stand for themselves but instead are interpreted in some special way. Some meta characters have a special meaning and are written inside square brackets. The meta characters are as follows:
A meta karakterek a reguláris kifejezések építőkockái. A meta karakterek speciális módon értelmezendőek. Némelyik meta karakternek speciális jelentése van és szögletes zárójelek közé vannak téve. A meta karakterek a következők:
| Meta character | Description |
|---|---|
| . | Period matches any single character except a line break. |
| [ ] | Character class. Matches any character contained between the square brackets. |
| [^ ] | Negated character class. Matches any character that is not contained between the square brackets |
| * | Matches 0 or more repetitions of the preceding symbol. |
| + | Matches 1 or more repetitions of the preceding symbol. |
| ? | Makes the preceding symbol optional. |
| {n,m} | Braces. Matches at least "n" but not more than "m" repetitions of the preceding symbol. |
| (xyz) | Character group. Matches the characters xyz in that exact order. |
| | | Alternation. Matches either the characters before or the characters after the symbol. |
| \ | Escapes the next character. This allows you to match reserved characters [ ] ( ) { } . * + ? ^ $ \ | |
| ^ | Matches the beginning of the input. |
| $ | Matches the end of the input. |
| Meta karakter | Leírás |
|---|---|
| . | A pont illeszkedik minden egyes karakterre kivéve a sortörést. |
| [ ] | Karakter osztály. Minden karakterre illeszkedik ami a szögletes zárójelek közt van. |
| [^ ] | Negált karakter osztály. Minden karakterre illeszkedik ami nincs a szögletes zárójelek közt. |
| * | Illeszkedik az őt megelőző szimbólum 0 vagy több ismétlődésére. |
| + | Illeszkedik az őt megelőző szimbólum 1 vagy több ismétlődésére. |
| ? | Opcionálissá teszi az őt megelőző szimbólumot. |
| {n,m} | Kapcsos zárójelek. Illeszkedik az őt megelőző szimbólum minimum "n" de nem több mint "m" ismétlődésére. |
| (xyz) | Karakter csoport. Illeszkedik az xyz karakterekre pontosan ilyen sorrendben. |
| | | Alternáció. Illeszkedik a szimbólum előtt és után álló karakterekre is. |
| \ | Escape-li a következő karaktert. A segítségével lefoglalt karakterekre is lehet illeszkedni [ ] ( ) { } . * + ? ^ $ \ | |
| ^ | A bevitel elejére illeszkedik. |
| $ | A bevitel végére illeszkedik. |
2.1 Full stop
2.1 Full stop
Full stop . is the simplest example of meta character. The meta character .
matches any single character. It will not match return or newline characters.
For example, the regular expression .ar means: any character, followed by the
letter a, followed by the letter r.
A full stop . a legegyszerűbb meta karakter példa. A . meta karakter illeszkedik
minden egyes karakterre. Nem fog illeszkedni a kocsi vissza és a sortörés karakterekre.
Például a .ar reguláris kifejezés jelentése: minden karakter, amit a aztán r követ.
".ar" => The car parked in the garage.
Test the regular expression Teszteld a reguláris kifejezést
2.2 Character set
2.2 Karakter osztályok
Character sets are also called character class. Square brackets are used to
specify character sets. Use a hyphen inside a character set to specify the
characters' range. The order of the character range inside square brackets
doesn't matter. For example, the regular expression [Tt]he means: an uppercase
T or lowercase t, followed by the letter h, followed by the letter e.
A szögletes zárójelekkel határozzuk meg a karakter osztályokat. A szögletes
zárójelek közt kötőjel karakterrel határozhatunk meg karakter tartományokat.
A karaktertartomány sorrendje nem számít. Például a [Tt]he reguláris kifejezés
jelentése: nagybetűs T vagy kisbetűs t amit egy h majd egy e betű követ.
"[Tt]he" => The car parked in the garage.
Test the regular expression Teszteld a reguláris kifejezést
A period inside a character set, however, means a literal period. The regular
expression ar[.] means: a lowercase character a, followed by letter r,
followed by a period . character.
Egy pont a karakter osztályon belül egyébként szó szerint pont-ot jelent. A
ar[.] reguláris kifejezés jelentése: kisbetűs a amit egy r aztán egy
pont . karakter követ.
"ar[.]" => A garage is a good place to park a car.
Test the regular expression Teszteld a reguláris kifejezést
2.2.1 Negated character set
2.2.1 Negált karakter osztályok
In general, the caret symbol represents the start of the string, but when it is
typed after the opening square bracket it negates the character set. For
example, the regular expression [^c]ar means: any character except c,
followed by the character a, followed by the letter r.
Általában a kalap szimbólum egy karakterlánc elejét jelenti, de ha egy nyitó
szögletes zárójel után áll, akkor negálja a karakter osztályt. Például a
[^c]ar reguláris kifejezés jelentése: minden karakter a c kivételével
ami után a aztán egy r betű áll.
"[^c]ar" => The car parked in the garage.
Test the regular expression Teszteld a reguláris kifejezést
2.3 Repetitions
2.3 Ismétlések
Following meta characters +, * or ? are used to specify how many times a
subpattern can occur. These meta characters act differently in different
situations.
A következő meta karaktereket +, * vagy ? arra használjuk, hogy meghatározzuk,
hányszor fordulhat elő az al-minta. Ezek a meta karakterek máshogy viselkednek
adott helyzetekben.
2.3.1 The Star
2.3.1 A csillag
The symbol * matches zero or more repetitions of the preceding matcher. The
regular expression a* means: zero or more repetitions of preceding lowercase
character a. But if it appears after a character set or class then it finds
the repetitions of the whole character set. For example, the regular expression
[a-z]* means: any number of lowercase letters in a row.
A * szimbólum az őt megelőző karakter nulla vagy több ismétlődésére illeszkedik.
A a* reguláris kifejezés jelentése: nulla vagy több ismétlődése az őt megelőző a
karakternek. De ha egy karakter osztály után áll akkor az egész karakterosztály
ismétlődését keresi. Például, a [a-z]* reguláris kifejezés jelentése: bármennyi
kisbetűs betű egy sorban.
"[a-z]*" => The car parked in the garage #21.
Test the regular expression Teszteld a reguláris kifejezést
The * symbol can be used with the meta character . to match any string of
characters .*. The * symbol can be used with the whitespace character \s
to match a string of whitespace characters. For example, the expression
\s*cat\s* means: zero or more spaces, followed by lowercase character c,
followed by lowercase character a, followed by lowercase character t,
followed by zero or more spaces.
A * szimbólum használható a . meta karakterrel .*, ez illeszkedik
bármilyen karakterláncra. A * szimbólum használható a whitespace karakterrel \s
együtt, hogy illeszkedjen egy whitespace-ekből álló karakterláncra. Például a
\s*cat\s*kifejezés jelentése: nulla vagy több szóköz, amit egy kisbetűs c,
aztán egy kisbetűs a, aztán egy kisbetűs t, amit még nulla vagy több szóköz követ.
"\s*cat\s*" => The fat cat sat on the concatenation.
Test the regular expression Teszteld a reguláris kifejezést
2.3.2 The Plus
2.3.2 A plusz
The symbol + matches one or more repetitions of the preceding character. For
example, the regular expression c.+t means: lowercase letter c, followed by
at least one character, followed by the lowercase character t. It needs to be
clarified that t is the last t in the sentence.
A + szimbólum illeszkedik az őt megelőző karakter egy vagy több ismétlődésére.
Például a c.+t kifejezés jelentése: kisbetűs c betű, amit legalább egy vagy
több t követ. Itt tisztázni kell hogy a t az utolsó t a mondatban.
"c.+t" => The fat cat sat on the mat.
Test the regular expression Teszteld a reguláris kifejezést
2.3.3 The Question Mark
2.3.3 A kérdőjel
In regular expression the meta character ? makes the preceding character
optional. This symbol matches zero or one instance of the preceding character.
For example, the regular expression [T]?he means: Optional the uppercase
letter T, followed by the lowercase character h, followed by the lowercase
character e.
A reguláris kifejezésben a ? meta karakter opcionálissá teszi az őt
megelőző karaktert. Ez a szimbólum az őt megelőző karakter nulla vagy egy
példányára illeszkedik. Például a [T]?he kifejezés jelentése: opcionális a
nagybetűs T, amit egy kisbetűs h, majd egy kisbetűs e követ.
"[T]he" => The car is parked in the garage.
Test the regular expression Teszteld a reguláris kifejezést
"[T]?he" => The car is parked in the garage.
Test the regular expression Teszteld a reguláris kifejezést
2.4 Braces
2.4 A kapcsos zárójelek
In regular expression braces that are also called quantifiers are used to
specify the number of times that a character or a group of characters can be
repeated. For example, the regular expression [0-9]{2,3} means: Match at least
2 digits but not more than 3 ( characters in the range of 0 to 9).
A reguláris kifejezésben a kapcsos zárójeleket annak meghatározására használjuk,
hogy egy karakter vagy egy karakter csoport hányszor ismétlődhet. Például a
[0-9]{2,3} kifejezés jelentése: minimum 2 de nem több mint 3 karakter a [0-9]
karaktertartományon belül.
"[0-9]{2,3}" => The number was 9.9997 but we rounded it off to 10.0.
Test the regular expression Teszteld a reguláris kifejezést
We can leave out the second number. For example, the regular expression
[0-9]{2,} means: Match 2 or more digits. If we also remove the comma the
regular expression [0-9]{3} means: Match exactly 3 digits.
Kihagyhatjuk a második számot. Például a [0-9]{2,} kifejezés jelentése:
2 vagy több számra illeszkedik. Ha a vesszőt is kitöröljük [0-9]{3}: Pontosan
3 számra illeszkedik.
"[0-9]{2,}" => The number was 9.9997 but we rounded it off to 10.0.
Test the regular expression Teszteld a reguláris kifejezést
"[0-9]{3}" => The number was 9.9997 but we rounded it off to 10.0.
Test the regular expression Teszteld a reguláris kifejezést
2.5 Character Group
2.5 Karakter csoportok
Character group is a group of sub-patterns that is written inside Parentheses (...).
As we discussed before that in regular expression if we put a quantifier after a
character then it will repeat the preceding character. But if we put quantifier
after a character group then it repeats the whole character group. For example,
the regular expression (ab)* matches zero or more repetitions of the character
"ab". We can also use the alternation | meta character inside character group.
For example, the regular expression (c|g|p)ar means: lowercase character c,
g or p, followed by character a, followed by character r.
A karakter csoport al-minták csoportja amik zárójelek közé (...) vannak írva.
Ahogy előbb már megbeszéltük, ha egy karakter után ismétlő karaktert rakunk, az
ismételni fogja az előtte lévő karaktert. De ha egy ismétlő karaktert egy karakter
csoport után rakunk, az ismételni fogja az egész csoportot. Például a (ab)*
kifejezés illeszkedik nulla vagy több ismétlődésére az ab karaktereknek.
Használhatunk alternáló meta karaktert | is a csoporton belül. Például a (c|g|p)ar
kifejezés jelentése: kisbetűs c, g vagy p karakter, amit egy a aztán
egy r karakter követ.
"(c|g|p)ar" => The car is parked in the garage.
Test the regular expression Teszteld a reguláris kifejezést
2.6 Alternation
2.6 Alternálás
In regular expression Vertical bar | is used to define alternation.
Alternation is like a condition between multiple expressions. Now, you may be
thinking that character set and alternation works the same way. But the big
difference between character set and alternation is that character set works on
character level but alternation works on expression level. For example, the
regular expression (T|t)he|car means: uppercase character T or lowercase
t, followed by lowercase character h, followed by lowercase character e or
lowercase character c, followed by lowercase character a, followed by
lowercase character r.
A reguláris kifejezésben a függőleges vonalat | alternálásra (választásra)
használjuk. Az alternálás olyan, mint egy feltétel több kifejezés közt. Most
azt gondolhatod, hogy a karakter osztály és az alternáció ugyan úgy működik.
De a fő különbség köztük, hogy a karakter osztály a karakterek szintjén működik,
az alternáció viszont a kifejezés szintjén. Például a (T|t)he|car kifejezés
jelentése: nagybetűs T karakter vagy kisbetűs t karakter, amit egy h és
egy e követ, VAGY kisbetűs c aztán a aztán r karakter.
"(T|t)he|car" => The car is parked in the garage.
Test the regular expression Teszteld a reguláris kifejezést
2.7 Escaping special character
2.7 Speciális karakter escape-elése
Backslash \ is used in regular expression to escape the next character. This
allows us to specify a symbol as a matching character including reserved
characters { } [ ] / \ + * . $ ^ | ?. To use a special character as a matching
character prepend \ before it.
A visszaper \ a reguláris kifejezésekben a következő karakter escape-elésére
való. Ez enged nekünk szimbólumokat vagy lefoglalt karaktereket { } [ ] / \ + * . $ ^ | ?
megadni. Egy speciális karakter egyező karakterként való megadásához tedd elé
a \ karaktert.
For example, the regular expression . is used to match any character except
newline. Now to match . in an input string the regular expression
(f|c|m)at\.? means: lowercase letter f, c or m, followed by lowercase
character a, followed by lowercase letter t, followed by optional .
character.
Például a . kifejezést az összes karakter, kivéve a sortörés illeszkedéséhez
használjuk. A (f|c|m)at\.? kifejezés jelentése: kisbetűs f, c vagy m, amit
egy kisbetűs a aztán egy kisbetűs t, amit egy opcionális . karakter követ.
"(f|c|m)at\.?" => The fat cat sat on the mat.
Test the regular expression Teszteld a reguláris kifejezést
2.8 Anchors
2.8 Horgonyok
In regular expressions, we use anchors to check if the matching symbol is the
starting symbol or ending symbol of the input string. Anchors are of two types:
First type is Caret ^ that check if the matching character is the start
character of the input and the second type is Dollar $ that checks if matching
character is the last character of the input string.
A reguláris kifejezésekben horgonyokat használunk, hogy megnézzük, az illeszkedő
szimbólum a kezdő vagy a záró szimbóluma-e a karakterláncnak. A horgonyoknak két
fajtájuk van: Az első a Kalap ^, ami megnézi, hogy az egyező karakter a karakterlánc
kezdő kerektere-e és a második a Dollár $, ami azt vizsgálja, hogy az egyező
karakter a karakterlánc utolsó karaktere-e.
2.8.1 Caret
2.8.1 Kalap
Caret ^ symbol is used to check if matching character is the first character
of the input string. If we apply the following regular expression ^a (if a is
the starting symbol) to input string abc it matches a. But if we apply
regular expression ^b on above input string it does not match anything.
Because in input string abc "b" is not the starting symbol. Let's take a look
at another regular expression ^(T|t)he which means: uppercase character T or
lowercase character t is the start symbol of the input string, followed by
lowercase character h, followed by lowercase character e.
A kalap ^ szimbólumot arra használjuk, hogy megnézzük, hogy az egyező karakter
a karakterlánc kezdő kerektere-e. Ha megadjuk a következő kifejezést: ^a,
akkor illeszkedik a abc karakterlánc a karakterére, mert az za első. De ha
megadjuk, hogy: ^b, ez nem fog illeszkedni az abc egyik részére sem, mert
nem b a kezdő karakter. Nézzünk meg egy másik kifejezést. ^(T|t)he jelentése:
nagybetűs T vagy kisbetűs t a kezdő karaktere a karakterláncnak, amit kisbetűs
h, majd kisbetűs e követ.
"(T|t)he" => The car is parked in the garage.
Test the regular expression Teszteld a reguláris kifejezést
"^(T|t)he" => The car is parked in the garage.
Test the regular expression Teszteld a reguláris kifejezést
2.8.2 Dollar
2.8.2 Dollár
Dollar $ symbol is used to check if matching character is the last character
of the input string. For example, regular expression (at\.)$ means: a
lowercase character a, followed by lowercase character t, followed by a .
character and the matcher must be end of the string.
A dollár $ szimbólumot arra használjuk, hogy megnézzük, hogy az egyező
karakter a karakterlánc utolsó karaktere-e. Például a (at\.)$ kifejezés
jelentése: egy kisbetűs a, amit egy kisbetűs t, amit egy . követ. És
ennek az egésznek a karakterlánc végén kell lennie.
"(at\.)" => The fat cat. sat. on the mat.
Test the regular expression Teszteld a reguláris kifejezést
"(at\.)$" => The fat cat. sat. on the mat.
Test the regular expression Teszteld a reguláris kifejezést
3. Shorthand Character Sets
3. Shorthand Karakter osztályok
Regular expression provides shorthands for the commonly used character sets, which offer convenient shorthands for commonly used regular expressions. The shorthand character sets are as follows:
A gyakran használt karakter osztályokra a reguláris kifejezésnek vannak rövidítései, amikkel kényelmesebben tudunk használni általános kifejezéseket. A shorthand karakter osztályok a következők:
| Shorthand | Description |
|---|---|
| . | Any character except new line |
| \w | Matches alphanumeric characters: [a-zA-Z0-9_] |
| \W | Matches non-alphanumeric characters: [^\w] |
| \d | Matches digit: [0-9] |
| \D | Matches non-digit: [^\d] |
| \s | Matches whitespace character: [\t\n\f\r\p{Z}] |
| \S | Matches non-whitespace character: [^\s] |
| Rövidítés | Leírás |
|---|---|
| . | Minden karakter a sortörésen kívül. |
| \w | Az alfanumerikus karakterekre illeszkedik: [a-zA-Z0-9_] |
| \W | A nem alfanumerikus karakterekre illeszkedik: [^\w] |
| \d | Számra illeszkedik: [0-9] |
| \D | Nem számra illeszkedik: [^\d] |
| \s | Whitespace karakterre illeszkedik: [\t\n\f\r\p{Z}] |
| \S | Nem whitespace karakterre illeszkedik: [^\s] |
4. Lookaround
4. Lookaround
Lookbehind and lookahead (also called lookaround) are specific types of
non-capturing groups (Used to match the pattern but not included in matching
list). Lookaheads are used when we have the condition that this pattern is
preceded or followed by another certain pattern. For example, we want to get all
numbers that are preceded by $ character from the following input string
$4.44 and $10.88. We will use following regular expression (?<=\$)[0-9\.]*
which means: get all the numbers which contain . character and are preceded
by $ character. Following are the lookarounds that are used in regular
expressions:
A lookbehind (hátranézés) és a lookahead (előrenézés) speciális típusai a
nem tárolt csoportoknak, amiket illeszkedésre használnak, de nincsenek
benne az illeszkedési listában. Az előrenézést akkor használjuk, ha feltételezzük,
hogy ezt a mintát egy másik minta előzi meg, vagy követi. Például kell nekünk
az összes szám ami előtt $ karakter áll a következő karakterláncból: $4.44 and $10.88.
Ezt a mintát fogjuk használni: (?<=\$)[0-9\.]*, aminek a jelentése: Szedd ki az
összes számot ami . karaktert tartalmaz és megelőzi egy $ karakter. A
következő lookaround-okat használhatjuk:
| Symbol | Description |
|---|---|
| ?= | Positive Lookahead |
| ?! | Negative Lookahead |
| ?<= | Positive Lookbehind |
| ?<! | Negative Lookbehind |
| Szimbólum | Leírás |
|---|---|
| ?= | Positive Lookahead |
| ?! | Negative Lookahead |
| ?<= | Positive Lookbehind |
| ?<! | Negative Lookbehind |
4.1 Positive Lookahead
4.1 Positive Lookahead
The positive lookahead asserts that the first part of the expression must be
followed by the lookahead expression. The returned match only contains the text
that is matched by the first part of the expression. To define a positive
lookahead, parentheses are used. Within those parentheses, a question mark with
equal sign is used like this: (?=...). Lookahead expression is written after
the equal sign inside parentheses. For example, the regular expression
(T|t)he(?=\sfat) means: optionally match lowercase letter t or uppercase
letter T, followed by letter h, followed by letter e. In parentheses we
define positive lookahead which tells regular expression engine to match The
or the which are followed by the word fat.
A pozitív előrenézés azt mondja, hogy a kifejezés első részét az előrenézés
kifejezésnek kell követnie. Az illeszkedés csak azt a szöveget tartalmazza, amire
a kifejezés első része illeszkedett. Pozitív előrenézést zárójelekkel definiálunk.
A zárójelek közt van a kérdőjel egy egyenlőségjellel, így: (?=...). Az előrenézés
kifejezést az egyenlőségjel után írjuk a zárójelek közé. Például a (T|t)he(?=\sfat)
jelentése: opcionális kisbetűs t vagy nagybetűs T, amit egy h aztán egy e
követ. A zárójelek közt definiáljuk a pozitív előrenézést ami megmondja a reguláris
kifejezés motornak, hogy illeszkedjen a The vagy the karakterláncokra, amelyeket
a fat karakterlánc követ.
"(T|t)he(?=\sfat)" => The fat cat sat on the mat.
Test the regular expression Teszteld a reguláris kifejezést
4.2 Negative Lookahead
4.2 Negative Lookahead
Negative lookahead is used when we need to get all matches from input string
that are not followed by a pattern. Negative lookahead is defined same as we define
positive lookahead but the only difference is instead of equal = character we
use negation ! character i.e. (?!...). Let's take a look at the following
regular expression (T|t)he(?!\sfat) which means: get all The or the words
from input string that are not followed by the word fat precedes by a space
character.
A negatív előrenézést akkor használjuk, ha az olyan illeszkedések kellenek,
amelyeket nem követ egy bizonyos minta. A negatív előrenézést ugyanúgy
definiáljuk mint a pozitív előrenézést, az egyetlen különbség, hogy az
egyenlőségjel = helyett negálást ! használunk: (?!...). Nézzük meg
a következő kifejezést: (T|t)he(?!\sfat), jelentése: szedd ki az összes
The vagy the szót, amelyeket nem követ a fat szó (amit még megelőz
egy szóköz).
"(T|t)he(?!\sfat)" => The fat cat sat on the mat.
Test the regular expression Teszteld a reguláris kifejezést
4.3 Positive Lookbehind
4.3 Positive Lookbehind
Positive lookbehind is used to get all the matches that are preceded by a
specific pattern. Positive lookbehind is denoted by (?<=...). For example, the
regular expression (?<=(T|t)he\s)(fat|mat) means: get all fat or mat words
from input string that are after the word The or the.
A pozitív hátranézést akkor használjuk, ha kell az összes illeszkedés, amit
egy megadott minta előz meg. A pozitív hátranézés így van jelölve: (?<=...).
A (?<=(T|t)he\s)(fat|mat) jelentése: szedd ki az összes fat vagy mat szót
amelyek a The vagy a the szavak után vannak.
"(?<=(T|t)he\s)(fat|mat)" => The fat cat sat on the mat.
Test the regular expression Teszteld a reguláris kifejezést
4.4 Negative Lookbehind
4.4 Negative Lookbehind
Negative lookbehind is used to get all the matches that are not preceded by a
specific pattern. Negative lookbehind is denoted by (?<!...). For example, the
regular expression (?<!(T|t)he\s)(cat) means: get all cat words from input
string that are not after the word The or the.
A negatív hátranézést akkor használjuk, ha kell az összes illeszkedés, amit nem
egy megadott minta előz meg. Jelölése: (?<!...). Például a (?<!(T|t)he\s)(cat)
kifejezés jelentése: szedd ki az összes olyan cat szót, amelyik nem a The vagy
a the szavak után van.
"(?<!(T|t)he\s)(cat)" => The cat sat on cat.
Test the regular expression Teszteld a reguláris kifejezést
5. Flags
5. Flag-ek
Flags are also called modifiers because they modify the output of a regular expression. These flags can be used in any order or combination, and are an integral part of the RegExp.
A flag-eket módosítónak hívják, mert módosítják a reguláris kifejezés kimenetét. Ezeket a flag-eket bármilyen sorban vagy kombinációban lehet használni, a RegExp szerves részét képezik.
| Flag | Description |
|---|---|
| i | Case insensitive: Sets matching to be case-insensitive. |
| g | Global Search: Search for a pattern throughout the input string. |
| m | Multiline: Anchor meta character works on each line. |
| Flag | Leírás |
|---|---|
| i | Kis-nagybetű érzéketlen: Beállítja, hogy az illeszkedés kis-nagybetű érzéketlen legyen. |
| g | Globális keresés: A bemeneti szövegben mindenütt keresi az illeszkedéseket. |
| m | Többsoros: A horgonyok az összes sorra működnek. |
5.1 Case Insensitive
5.1 Kis-nagybetű érzéketlen
The i modifier is used to perform case-insensitive matching. For example, the
regular expression /The/gi means: uppercase letter T, followed by lowercase
character h, followed by character e. And at the end of regular expression
the i flag tells the regular expression engine to ignore the case. As you can
see we also provided g flag because we want to search for the pattern in the
whole input string.
Az i módosító beállítja, hogy az illeszkedés ne legyen kis-nagybetű érzékeny.
Például a /The/gi kifejezés jelentése: nagybetűs T amit kisbetűs h, majd e
követ. A kifejezés végén az i megmondja a reguláris kifejezés motornak, hogy
hagyja figyelmen kívül a betűk méretét. Ahogy látod, megadtuk a g flag-et, mert
az egész bemeneti szövegben akarjuk keresni az illeszkedéseket.
"The" => The fat cat sat on the mat.
Test the regular expression Teszteld a reguláris kifejezést
"/The/gi" => The fat cat sat on the mat.
Test the regular expression Teszteld a reguláris kifejezést
5.2 Global search
5.2 Globális keresés
The g modifier is used to perform a global match (find all matches rather than
stopping after the first match). For example, the regular expression/.(at)/g
means: any character except new line, followed by lowercase character a,
followed by lowercase character t. Because we provided g flag at the end of
the regular expression now it will find all matches in the input string, not just the first one (which is the default behavior).
A g módosítót arra használjuk, hogy globálisan keressünk illeszkedéseket.
(Megkeresi az összes előfordulást, nem áll meg az első egyezés után). Például
a /.(at)/g kifejezés jelentése: minden karakter, kivéve a sortörést, amelyet
a és t követ. Mivel megadtuk a g flag-et, az összes ilyenre fog illeszkedni,
nem csak az elsőre (ami az alapértelmezett viselkedés).
"/.(at)/" => The fat cat sat on the mat.
Test the regular expression Teszteld a reguláris kifejezést
"/.(at)/g" => The fat cat sat on the mat.
Test the regular expression Teszteld a reguláris kifejezést
5.3 Multiline
5.3 Többsoros
The m modifier is used to perform a multi-line match. As we discussed earlier
anchors (^, $) are used to check if pattern is the beginning of the input or
end of the input string. But if we want that anchors works on each line we use
m flag. For example, the regular expression /at(.)?$/gm means: lowercase
character a, followed by lowercase character t, optionally anything except
new line. And because of m flag now regular expression engine matches pattern
at the end of each line in a string.
Az m módosítót a többsoros illeszkedésekhez használjuk. Ahogy előzőleg beszéltük,
a horgonyokat (^, $) arra használjuk, hogy megnézzük, a minta az eleje, vagy a vége-e
a vizsgált karakterláncnak. De ha azt szeretnénk, hogy a horgonyok az összes soron
működjenek, használjuk az m módosítót. Például a /at(.)?$/gm kifejezés jelentése:
kisbetűs a karakter, amit egy kisbetűs t követ, amit opcionálisan bármi követhet,
kivéve sortörés. És az m flag miatt a reguláris kifejezés motor az összes sor
végéig keres illeszkedést.
"/.at(.)?$/" => The fat
cat sat
on the mat.
Test the regular expression Teszteld a reguláris kifejezést
"/.at(.)?$/gm" => The fat cat sat on the mat.
Test the regular expression Teszteld a reguláris kifejezést
Contribution
Hozzájárulás
-
Report issues
-
Open pull request with improvements
-
Spread the word
-
Reach out to me directly at ziishaned@gmail.com or

-
Jelents hibákat
-
Nyiss pull request-eket fejlesztésekkel
-
Hírdesd az igét
-
Érj el közvetlenül itt: ziishaned@gmail.com vagy
License
Licenc
MIT © Zeeshan Ahmed